Machine learning
Our view on Machine Learning Operations (MLOps) for video analytics
Machine learning or computer vision at scale is one of the key motivations of the entire Kerberos Enterprise Suite. All services going from Kerberos Agents, Kerberos Vault to Kerberos Hub are designed in such a way that you can scale them independently of each other.
The design principle of Kerberos Enterprise Suite allows to decouple videos streams from any CPU or GPU workloads, through the creation of video chunks, queueing and event messaging. This is perfect for GPU workloads such as machine learning or other AI services.

Machine learning and Computer Vision with Kerberos Vault
The problem we solve
The complexity not only starts with the creation of a machine learning model, to solve or compute a specific business case, it also starts at the deployment of the machine learning model, and it even becomes more complex when you scale over time.
Especially in the video analytics space, where we apply machine learning to video streams, and more specific videos (mp4) or images (JPEG), there are many challenges.
- How do you scale the recording of video streams?
- How do GPUs process video streams? One by one?
- How do you scale your GPUs, and add more in the future?
- What happens if you add more video streams, do you need to add more GPUs?
Previously challenges is where we at Kerberos.io bring value through the Kerberos Enterprise Suite. We provide an elegant and scalable design for supporting your every-growing machine learning use cases. Read more below.
Video chunks
Kerberos Agents are responsible for recording video streams into small chunks, mp4s, of which you can configure the length of the recording; pre and post recording. The main motivation of doing this is that small chunks of videos are easier to process and distribute across different workloads. Therefore, video chunks are the building blocks and basis of the scale Kerberos brings.
Queueing and events
Video chunks prepared by one or more Kerberos Agents are sent to Kerberos Vault where they are persisted in one or more storage providers. The key thing is that they stored through a central application, Kerberos Vault, which has the ability to trigger integrations such as a Kafka broker.
Consuming and interfere
Once events are being generated, they are ready to be consumed by one or more consumers. Having this publish and subscribe mechanism, for example Kafka, you have one or more producers (Kerberos Vault replicas) and one or more consumers (ML clients). This allows one to scale the number of consumer and workloads as the number of events, and thus recordings, are increasing.
NVIDIA operator
Having multiple consumers, I believe we can agree that scaling becomes trivial and thanks to Kubernetes more flexible. But what about GPUs, how do we scale that?
This is where the NVIDIA operator pops up. NVIDIA released a Kubernetes operator called the NVIDIA operator, that takes control over GPU allocation and assignment to workloads.
The operator solves two main challenges:
Hardware: a system or infrastructure engineer can just insert another NVIDIA GPU in one of the PCIE slots, and the Kubernetes cluster / NVIDIA operator will make it part of the GPU pool.
Datascience: engineers can build and deploy machine learning models without the need of specifying a particular GPU. The NVIDIA operator will handle that allocation, and make sure one of the GPUs in the pool is assigned to the requested workload.
Installation
The installation of the NVIDIA operator can be found here, with a couple of examples of how to integrate a workload (a machine learning model) with Kerberos Vault.
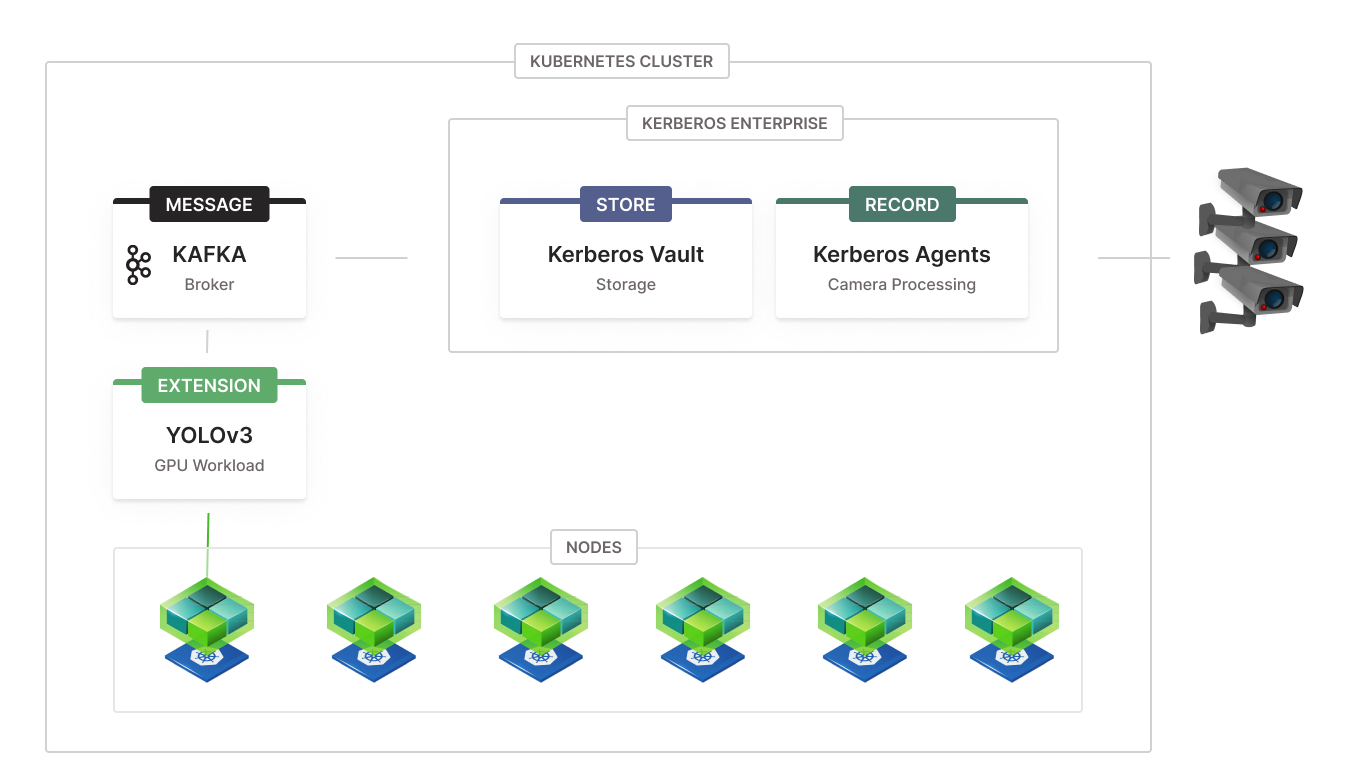
The NVIDIA operator brings scale to your GPUs.
An example
The goal of the integration feature of Kerberos Vault is to allow an enterprise to bring its custom logic, while relying on a stable and scalable video management system. One can build its own notification service, triggering IoT or other kind of sensors, or execute a custom machine learning model trying to detect specific objects, patterns or actions in a recording. As described below you can found a complete aswer here.
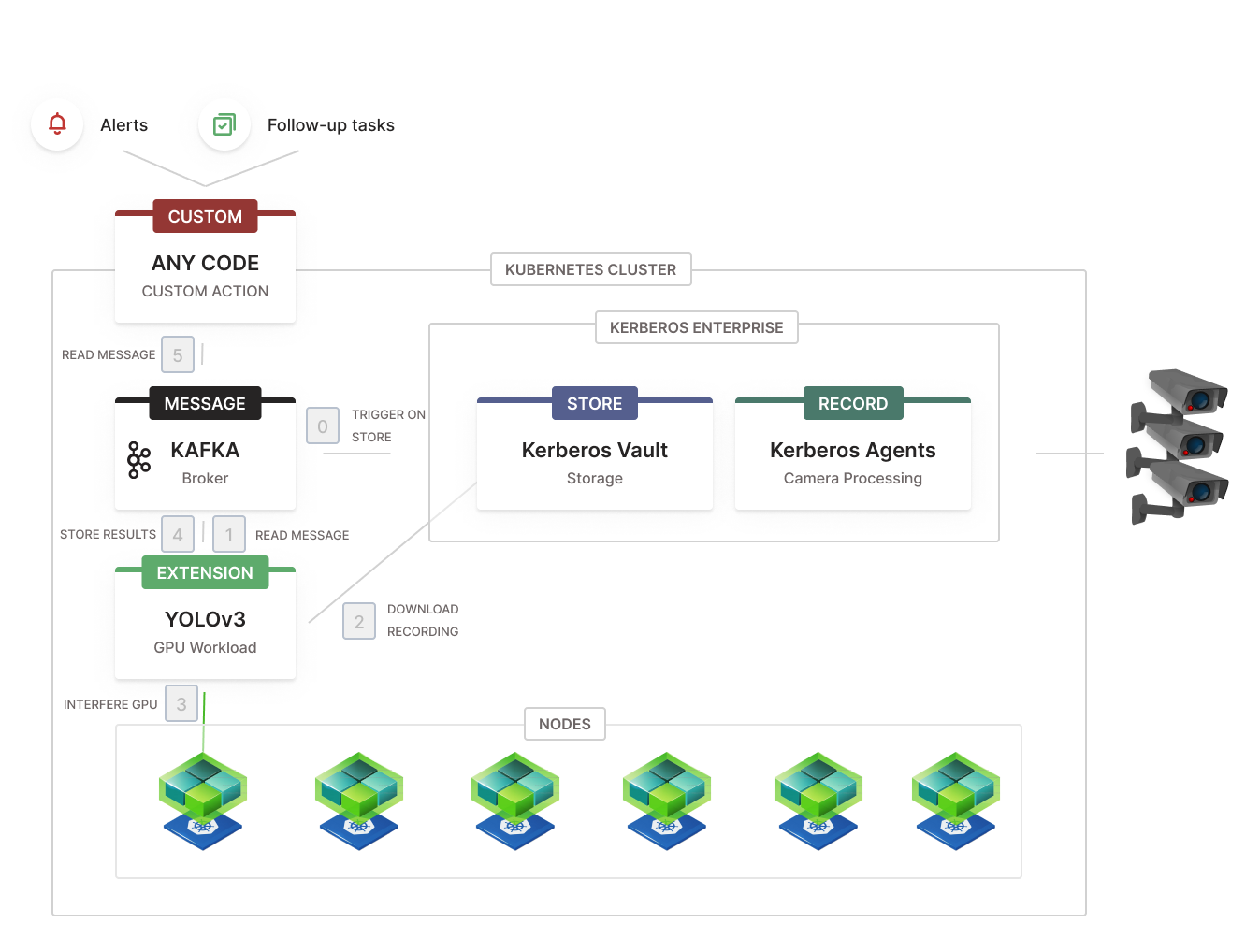
The NVIDIA operator brings scale to your GPUs.
So having above example let us get a bit more concrete on how this is functioning. We will describe the different steps and what is happening under the hood.
Step 0: Small chunks of recordings are created, persisted in a storage provider, and a message is sent to a Kafka topic.
Step 1: an extension/workload which executes the YOLOv3 model is consuming Kafka messages from a topic, produced by Kerberos Vault.
Step 2: Before execution of the model, the extension consumes the relevant messages from a specific topic, and downloads the video chunk from Kerberos Vault in memory.
Step 3: The NVIDIA operator has assigned one of the GPUs from the GPU pool to the extension. The assigned GPU is used to execute the YOLOv3 model on the video chunk.
Step 4: Metadata is computed, for example number of objects detected, and is injected into a resulting Kafka topic.
Step 5: An additional (optional) microservice is reading from the resulting Kafka topic, and execute more specific business logic: alerting through sensors or notifications, creation of entries into a support or CCTV system, etc.
Scale and expand
As illustrated in previous example, it should become clear that by chunking videos, distributing them over a flexible pool of GPUs, allows to provide a scalable and flexible way. Video streams are decouples from GPUs, and each of them can be scaled independently. Video chunks created by one or more Kerberos Agents are distributed over a pool of GPUs without knowing upfront which GPU will process which video chunk from which Kerberos Agent.

GPUs and CPUs are decoupled. Any recording, independent of any video stream, will be distributed to the GPU pool.
Machine learning at the edge
Execution of your machine learning at the edge will give you a lot of advantages and allow you to distribute and scale more easily and efficient. By executing at the edge, you will:
- Lower cloud storage and compute,
- better latency and response times,
- real distributed processing and computing power,
- ability to tune and provide only the hardware required.
Let your data scientist do datascience
Your data scientist want to do datascience, they don’t want to set up infrastructure, install GPUs or even modify their models and programming language to select a specific GPU. Hardware and more specific GPUs should remain transparent.
The entire design behind the Kerberos Enterprise Suite is to support and implement the concept of MLOps. This means that your data scientist should focus on the data science and the creation of specific models.
When delivering or releasing a model, a data scientist should only be required to make a build, a container, of his release and deploy that inside a Kubernetes cluster. Nothing more than that.
A data scientist should make the assumption that once it is deployed:
- it is automatically scaled across the different hardware components (GPUs).
- it just runs and has fail over and high-availability enabled by default
- only works with video chunks and metadata, but not the actual video streams.